Notes on vibe coding 1
Kaiser tries vibe coding to archive his entire blog. How did it go?
Large language models (LLMs) have evolved to the point where they become useful tools for writing computer code.
Recently, as a result of Typepad's impending shutdown (link), I found a perfect opportunity to explore "vibe coding" using LLMs. Vibe coding can mean many things to many people so let me just define what I mean by vibe coding. It is a hands-off process of coding, in which the human's role is limited to steering and guiding. The human coder is not actually writing code; in fact, the coder isn't even reading code. In the end, the code is entirely written by AI.
(The million-dollar question: does this mean vibe coding can be done by someone who knows no coding at all? I'll come back to this question at the end.)
What is vibe coding not? My definition deliberately excludes LLMs as "StackExchange on steriods". StackExchange has been a super-useful Q&A website in which developers ask questions to other developers who supply answers, frequently filled with insights, extensions, code fragments, and commentary. Not surprisingly, StackExchange data were used to train LLMs (link). Therefore, if one has a coding question today, one can ask the LLM, instead of searching for the answer on StackExchange. The AI has effectively "read" the relevant StackExchange posts, and responded with key information. Tools like Co-Pilot makes it possible to do the above without leaving the code editor.
That's not what I'm exploring in my vibe coding experiment. In this StackExchange on steroids mode, the coder is still in control of the code; the coder has probably written a good portion of it, and the coder most definitely has read everything through. While this path is viable, and valuable, it certainly won't lead to the promised land of enabling a non-coder to produce code.
Now, let me define my experiment. In view of Typepad's imminent shutdown, I want to archive all my posts, stretching back nearly 20 years. There are several thousand image-heavy posts. The general idea is to "scrape" my own blog. In the Big Data era, scraping has become an everyday skill: this is how Google, and ChatGPT collect data to power its search engine and its AI chatbot respectively. The process of scraping is the sequential loading of large numbers of webpages in order to extract and store the relevant data from each page.
Scraping code is annoying to write because it requires a deep understanding of the structure of these web pages. Website design differ: consider where the navigation column is placed, how images are interspersed with text, whether there are buttons, forms, popups, etc. etc. For example, if I want to save every image of every blog post, I'd need to delve into the HTML code to decipher how the image tags are organized, and then write custom code to navigate such structure. I'd also be hoping that Typepad hasn't altered this structure during the last 20 years, or else my scraping code has to know what these different structures are, and then try guessing which particular one applies to any given page.
Web scraping is also somewhat controversial. Many website operators try to block it. Scraping generates fake traffic to websites; scraped pages are loaded but aren't actually read by humans; thus, websites pay service providers, who deliver the pages to visitors across the networks, for fake traffic that does not produce any revenues (ads, product sales, etc.). For this reason, and also to protect their data, most websites impose limits on scraping; some operators even attempt to stop all scrapers by predicting whether a page load request comes from scrapers. (As a general rule, though, the louder company X complains about other people scraping its website, the more likely Company X is actively scraping other websites, busily working around these blocking tactics. Looking at you: Google, Facebook, OpenAi, etc.)
Why do I think vibe coding might fit this project well? First, since AI models have shown great ability parsing the structure of human speech, they should be able to dissect the HTML code, which adheres to rules that are even more rigid than grammar. Second, AI coders probably have seen a lot of scraping code, since it's such a common activity, so that it should know how to handle blocking adversaries. Both hypotheses would come true; but my journey is just getting started.
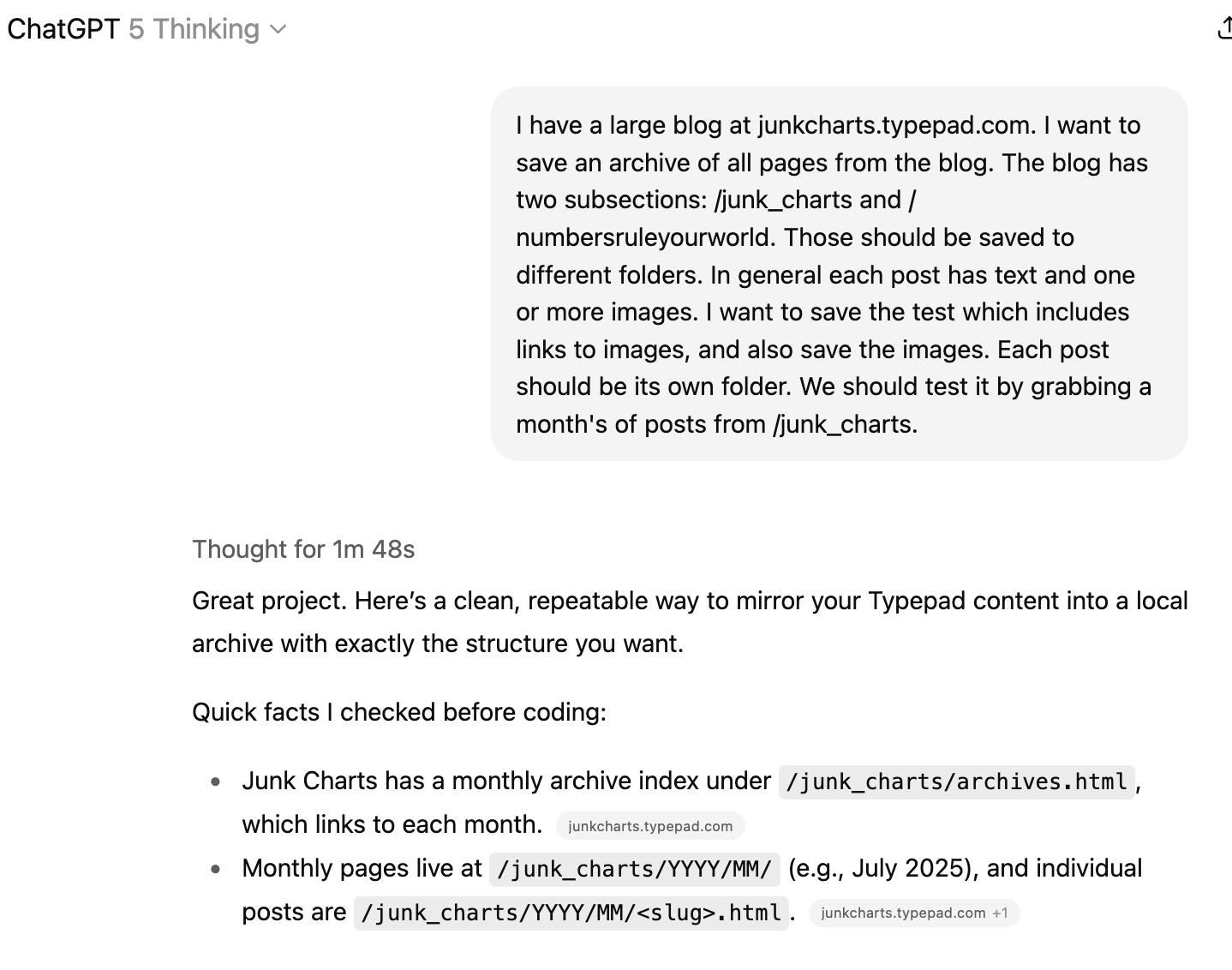
Here is the first prompt I sent to ChatGPT (at the start, I used the recently released GPT 5 Thinking model):
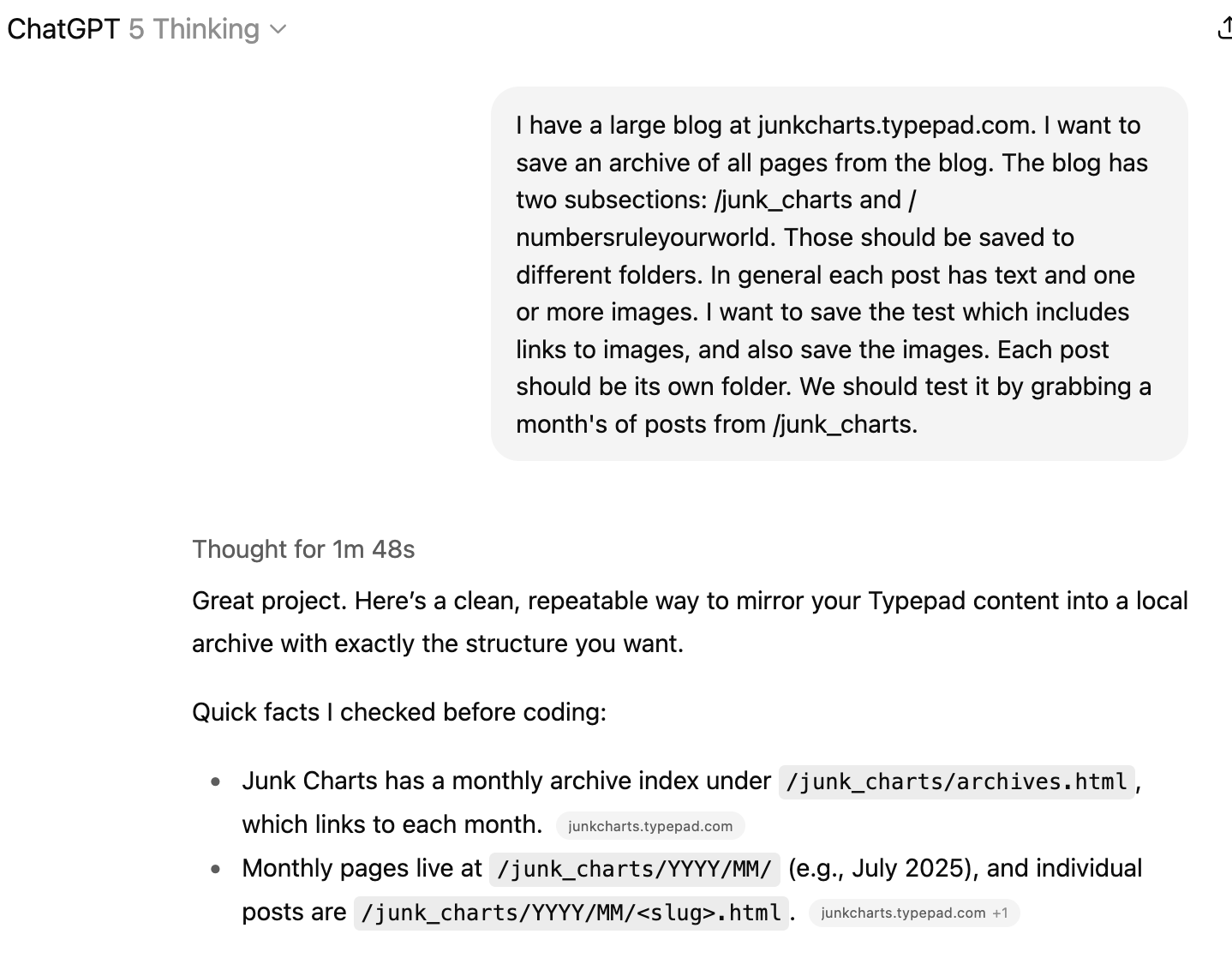
The prompt mostly describes the high-level objective of my project, offering key context that must not be missed (e.g. I run two blogs under one domain name). I didn't mention countering potential blocking or parsing HTML structure because I expect that any self-respecting AI coder knows about these challenges. I include context specific to my scraping request. One such detail is the need to associate images with each post. It would be a nightmare if I end up with an image folder containing thousands of files, untethered from the text, so I suggested in the prompt to make a new folder for each blog post. I'm curious whether the AI coder will heed this advice, or will it recommend a better way of linking up images and text after divining the motivation for this special request?
The response looks very promising. GPT returns a file with code inside (a python "script"), and also provides instructions for how to run the script.
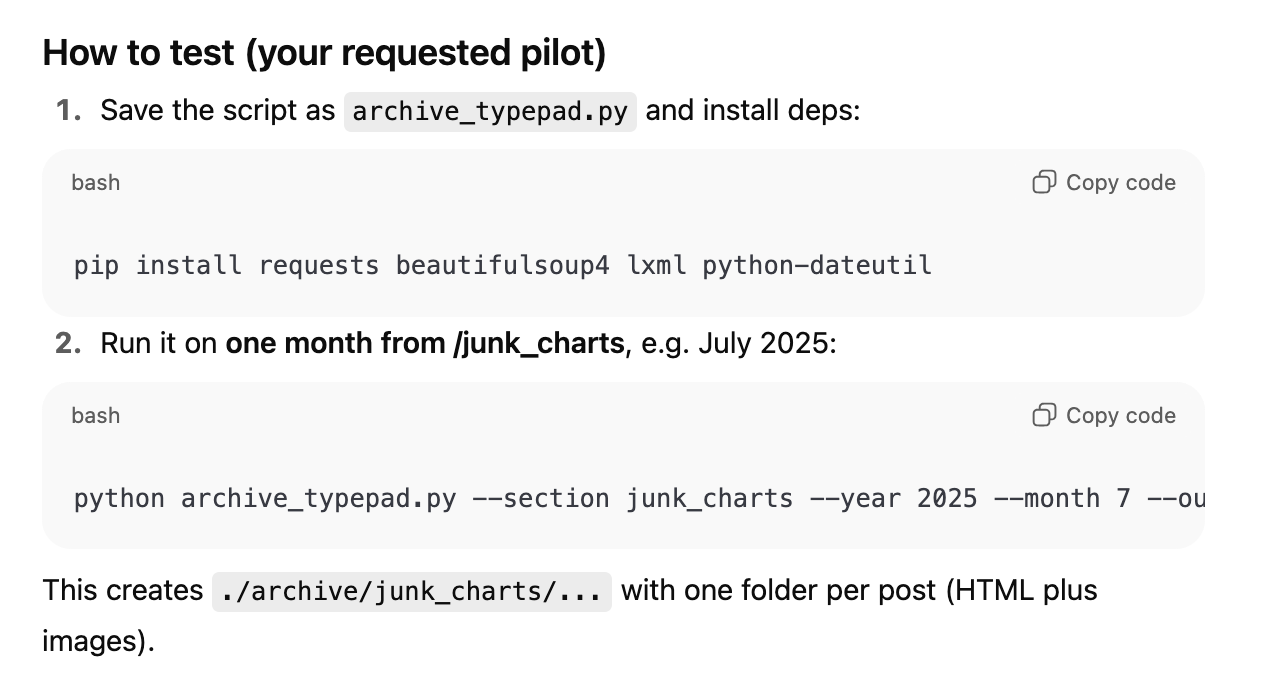
Time out to think about where we are.
If you don't know any coding at all, you'd have some difficulty following those instructions. Where are you supposed to type in those commands? What is this "bash"? You probably don't have the "pip" program installed either. If the program succeeded, from where do you fetch the output? GPT actually tries to help by saying "./archive/junk_charts/..." but a non-coder would be able to decipher those words! It's not hard to pick up these concepts but you do have to learn them.
I'd like to return your attention to the first prompt shown above, in which I also clipped the top part of the AI's response. The section you can see explains how the scraper will nevigate my blog. Remember that it has to visit every blog post sequentially. While researching my prompt, the AI visited my blog and discovered that old posts are grouped by month, with all posts published in a given month aggregated on the same monthly page. There exists also a top-level index page, called archive.html, that contains links to each monthly page. Thus, the scraper first visits that index page, and using it as a map, it loads each monthly page, and on each monthly page, it extracts the required text and images. This scraping strategy makes sense to me.
Elsewhere in that GPT response, I noticed mention of "rate limiting" and a possible "retry" mechanism, so the AI is definitely "aware" of potential blocking. Therefore, both my hypotheses came true - I didn't have to include these "obvious" items in my prompt.
In the first prompt, I asked GPT to build a testing mode so I can run the code on one month's worth of posts before rolling it out to thousands of posts. GPT made this testing mode as requested.
After reading the rationale of the GPT response, I don't have any complaints. So I downloaded the script, and ran the code.
[to be continued]
P.S. [9/23/2025] Part 2 and Part 3 are now posted. Remember to change your bookmarks to https://www.junkcharts.com.